2025.05.08
Part12. 파이토치
- Chapter.04 Modeling
- 01_modeling
- Chapter.05 Model 학습
- 01_training
- 02_model save
Pytorch의 모델링
Pytorch에서 모델을 정의하는 방법은 두 가지가 있다.
- nn.Sequential 방법
- Sub-Class of nn.Module 방법
torch.nn 모듈
관련 패키지와 모듈을 import
import torch
from torch import nn
import torch.nn.functional as F
nn 모듈은 tensorFlow와 다르게 input channel을 입력받는다. TensorFlow에서는 output channel만 받고 input은 자동으로 정해진다.


nn.Sequential 방법
우선 GPU를 지정하여 할당한다.
## device 생성 및 GPU 할당
device = torch.device("cuda" if torch.cuda.is_available() else 'cpu')
device
아래와 같이 모델을 선언하고 사용할 수 있다.
model = nn.Sequential(
nn.Linear(784, 15),
nn.Sigmoid(),
nn.Linear(15, 10),
nn.Sigmoid()
)
model
print 함수를 이용하여 모델을 정보를 볼 수 있다.

모델을 조금 더 상세히 보려면 torchsummary 패키지를 이용할 수 있다. conda 채널에서는 설치가 안되고, pip3 에서 설치할 수 있다.
# !pip3 install torchsummary
import torchsummary
model.to("cuda")
torchsummary.summary(model, (784,), device="cuda")
# (784,) : 입력채널 명시
# device : torchsummary는 모델을 자동으로 옮기지 않는다?
# 오류뜨면 model.to("cuda") 추가필요요
nn.module Sub Class
대부분의 Pytorch 모델은 해당 방식으로 선언된다.
# input = (1, 28, 28)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 20, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(20, 50, kernel_size=3, padding=1)
self.fc1 = nn.Linear(2450, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
x = x.view(-1, 2450)
x = F.relu(self.fc1(x))
x = F.log_softmax(self.fc2(x), dim=1)
return x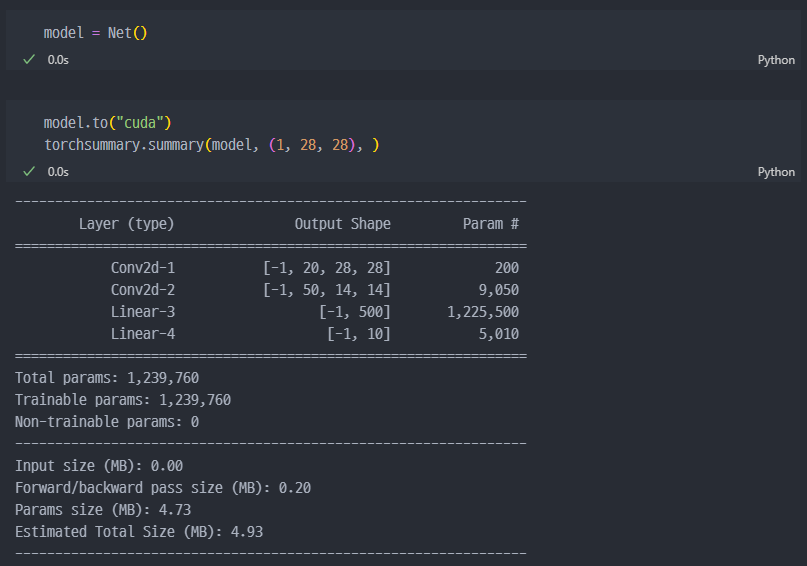
일단 여기서 첫 번째 Linear 레이어에서 Input size가 2450은 아래의 과정으로 계산하여 넣어야 한다. 강의시간에는 4900 으로 기재하였지만, 일단 지피티 형님께서 4900이 아닌 2450이 맞다고 알려주어 변경하였다.
출력 크기의 계산 및 kernel_size와 stride, padding의 상관관계 설명


간단한 ResNet 구현
ResNet에서는 input과 Output을 더하는 Shorcut 개념이 들어간다. 이를 Residual Block이라 하며, 아래처럼 구현할 수 있다.
class ResidualBlock(nn.Module):
def __init__(self, in_channel, out_channel):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channel, out_channel, kernel_size=1, padding=0)
self.conv2 = nn.Conv2d(out_channel, out_channel, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(out_channel, out_channel, kernel_size=1, padding=0)
# in 과 out 채널이 달라 더하기 전 사전작업
if in_channel != out_channel:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel_size=1, padding=0)
)
else:
self.shortcut = nn.Sequential()
def forward(self, x):
out = F.relu(self.conv1(x))
out = F.relu(self.conv2(out))
out = F.relu(self.conv3(out))
out += self.shortcut(x)
return out
그 후 ResNet를 구현해보면..
class ResNet(nn.Module):
def __init__(self, color='gray'):
super(ResNet, self).__init__()
if color == "gray":
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1, stride=1)
elif color == "rgb":
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1, stride=1)
self.resblock1 = ResidualBlock(32, 64)
self.resblock2 = ResidualBlock(64, 64)
self.avgpool = nn.AdaptiveAvgPool2d((1,1))
self.fc1 = nn.Linear(64, 64)
self.fc2 = nn.Linear(64, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = self.resblock1(x)
x = self.resblock2(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = F.relu(self.fc1(x))
x = self.fc2(x)
x = F.log_softmax(x, dim=1)
return x
Training Logic
데이터 준비 및 모델구현
이번에는 Pytorch에서 학습로직에 대해서 알아보는 시간이다.
지금까지와 마찬가지로, 관련 패키지들을 import 하고 device에 GPU를 할당한다.
import torch
from torch import nn
from torch import optim
import torch.nn.functional as F
from torchvision import datasets, transforms
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
연습에서 사용할 MNIST Datasets을 받아준다.
import torch.utils
batch_size = 32
## datasets load
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('datasets/', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.5,), std=(0.5,))
])),
batch_size=batch_size,
shuffle=True
)
이전에도 몇 번 나왔지만, 헷갈리는 개념 몇 가지만 다시 보고 가면..
1) transforms.Compose( ) : 코드의 순서대로 데이터의 전처리 과정을 진행하게 묶어주는 함수.
2) ToTensor( ) : PIL , Numpy 배열들은 Pytorch의 Tensor 배열로 변경해 주면서, 정규화도 같이 진행한다. (0~255 → 0~1 값)
3) transforms.Normalize( ) : 평균과 표준편차 기준으로 노멀라이즈(정규화, 단 위 정규화와 조금 다르다). 이 경우 픽셀을 0~1값들을 -1~1 사이 값으로 변경한다. mean=(0.5,) 의 경우 흑백이미지에서 적용하고, 컬러이미지에서는 mean=(0.5,0.5,0.5) 와 같이 할당해야 한다.
$$output = \frac{input - mean}{std}$$
그리고 이전에 학습했던 것처럼 Residual Block과 ResNet을 서브클래스 방식으로 구현한다.
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels):
super(ResidualBlock, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=1, padding=0)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(out_channels, out_channels, kernel_size=1, padding=0)
if in_channels != out_channels:
self.shorcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, padding=0)
)
else:
self.shorcut = nn.Sequential()
def forawrd(self, x):
out = F.relu(self.conv1(x))
out = F.relu(self.conv2(out))
out = F.relu(self.conv3(out))
out = out + self.shorcut(x)
class ResNet(nn.Module):
def __init__(self, color='gray'):
super(ResNet, self).__init__()
if color == 'gray':
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)
elif color == 'rgb':
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1)
self.resblock1 = ResidualBlock(32, 64)
self.resblock2 = ResidualBlock(64, 10)
self.avgpool = nn.AdaptiveAvgPool2d((1,1))
self.fc1 = nn.Linear(64, 64)
self.fc2 = nn.Linear(64, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = self.resblock1(x)
x = self.resblock2(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = F.relu(self.fc1(x))
x = self.fc2(x)
x = F.log_softmax(x, dim=1)
return x
Learning Rate Scheduler
# 우선 옵티마이져 선언
optimizer = optim.Adam(model.parameters(), lr=0.003)
from torch.optim.lr_scheduler import ReduceLROnPlateau
scheduler = ReduceLROnPlateau(optimizer, mode = 'min', verbose=True)
* ReduceLROnPlateau가 val_loss를 보고, 더 이상 줄어들지 않으면 learning rate를 줄임.
def train_loop(dataloader, model, loss_fn, optimizer, scheduler, epoch):
model.train()
size = len(dataloader)
for batch, (x, y) in enumerate (dataloader):
x, y = x.to(device), y.to(device)
pred = model(x)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch %100 ==0:
current_lr = optimizer.param_groups[0]['lr']
print(f"Epoch {epoch} : [{batch} / {size}] loss : {loss.item():.4f} lr : {current_lr:.6f}")
scheduler.step(loss)
for epoch in range(5):
loss = train_loop(train_loader, model, F.nll_loss, optimizer, scheduler, epoch)
print(f'epoch : {epoch} loss : {loss}')
lr이 변하지는 않았지만, 이렇게 학습 결과(loss)에 따라 learning rate를 변동시킬 수 있다.
model Save
Save, Load
TensorFlow와 마찬가지로 Pytorch에서도 모델을 Save하거나 Load 할 수 있다.
모델의 Weights만 저장/불러오기 하는 건 아래와 같다.
- 저장 : torch.save(model.state_dict(), 'model_weights.pth')
- 불러오기 : model.load_state_dict(troch.load('model_weights.pth'))
Weights와 모델의 구조를 함께 저장하거나 불러오러면..
- 저장 : torch.save(model, 'model.pth')
- 불러오기 : model = torch.load('model.pth')
CheckPoint
모델을 학습하다 보면, 계속하지 못하고 중간에 잠시 멈추었다가 다시 학습을 재개하거나 또는 중간중간 진행과정을 저장해야 될 수 있다. 이럴 때 checkpoint를 사용한다.
## checkpoint
checkpoint_path = 'checkpoint.pth'
torch.save({
'epoch' : epoch,
'model_state_dict' : model.state_dict(),
'optimizer_state_dict' : optimizer.state_dict(),
'loss' : loss
}, checkpoint_path)
위처럼 4번째 epoch까지 학습 후에 CheckPoint를 저장하였다. 이후 아래처럼 다시 Load하여 확인하거나 학습을 재개할 수 있다.
model2 = ResNet().to(device)
optimizer2 = optim.Adam(model2.parameters(), lr=0.03)
checkpoint = torch.load(checkpoint_path)
checkpoint
checkpoint는 dict 형태이므로 keys 값을 확인할 수 있다.

저장된 정보들을 모델로 다시 보내고, 아래와 같이 학습을 재개할 수 있다.
model2.load_state_dict(checkpoint['model_state_dict'])
epoch = checkpoint['epoch']
optimizer2.load_state_dict(checkpoint['optimizer_state_dict'])
loss = checkpoint['loss']
for epoch in range(checkpoint['epoch'] + 1, checkpoint['epoch'] + 6): # epoch 5부터 9까지
loss = train_loop(train_loader, model2, F.nll_loss, optimizer2, scheduler, epoch)
print(f'epoch : {epoch} loss : {loss}')
'Bootcamp_zerobase > Pytorch' 카테고리의 다른 글
| Pytorch 데이터 다루기 (1) | 2025.05.28 |
|---|---|
| Pytorch 모델 학습 (0) | 2025.04.28 |
| 최적화 및 미분 (0) | 2025.04.27 |
| Tensor 다루기 (1) | 2025.04.27 |
| Pytorch #4 : 식물잎 사진으로 질병분류 (0) | 2025.04.26 |