
2024.12.23
Part 11. 텐서플로
- Chapter 02. 최적화
01. 자동미분
02. Linear regression (1)
03. Linear regression (2)
04. perceptron
최적화
자동미분
- tf.GradientTape
- tf.GradientTape은 컨텍스트(context) 안에서 실행된 모든 연산을 테이프(tape)에 "기록"
- 그 다음 TesnsorFlow는 후진 방식 자동 미분 (reverse mode differentiation)을 사용해 테이프에 "기록된" 연산의 그래디언트를 계산
Scalar를 Scalar로 미분

y = x**2 이다. x는 3이므로 y는 9이다. 미분하게 되면 x**2의 식이 2x로 변경되며, x는 3 이므로 미분값(리턴값)은 6이 된다.
Scalar를 Vector로 미분
참고홈페이지 : https://pinkwink.kr/1373
persistent=True 옵션 진행 시, 해당 객체 사용 이후 반드시 del tape 적용해야지 메모리 누수 방지됨.
자동미분 컨트롤 하기
- tf.Variable 만 기록합니다
- A Variable + tensor는 tensor를 반환
- trainable 조건으로 미분 기록 제어

Linear regression (1)
선형회귀는 앞단에서도 여러번 나왔지만, 결국 기존의 데이터 값들의 추세(?)를 찾는것 이다. 집값 예측과 같이 기존의 데이터와 어떠한 추세선에 대한 직선 거리의 합이 가장 적은 선(기울기 및 편향)을 찾는것 이다.
기본 셋팅
가상데이터셋
가상 데이터셋 생성 및 scatter로 시각화하기



학습진행
- 실제로 목표하는 값은 y = X * W_true + B_true + noise 라는 그래프이다.
- W_true 는 3, B_true는 2로 셋팅하였다.
- 학습을 위한 임의의 w, b 값은 각각 5.0 과 0.0으로 셋팅하였다.
- learning_rate는 0.03를 부과하였다. 모델이 매 학습 단계에서 w와 b를 얼마나 빠르게 업데이트할지 결정하는 학습률.


학습 진행 후 w, b 그리고 loss 값들이 학습때마다 어떻게 움직이는 지를 그래프로 보면.
( 코드는 동일하다 )




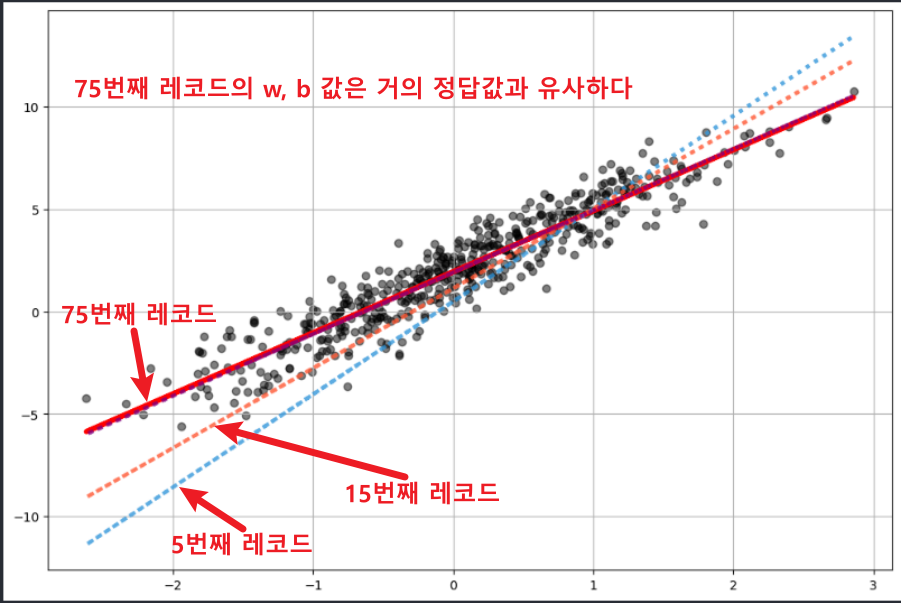
- w는 3에 수렴하고, b는 2에 수렴하는 것을 볼 수 있다. W_true 와 B_true값에 거의 근접한다.
- 하지만 굳이 10000번까지 학습은 필요없다, 200번 이후로는 거의 움직이지 않기에 200~300번 학습만하면 충분함을 알 수 있다.
- loss는 1에 거의 수렴하는 것을 알 수 있다.
해당 코드는 오차의 역전파에 해당하는 기초코드이기 때문에 지속해서 고민해보는 것이 좋다.
w, b 값이 어떻게 이동하는지 그래프로 확인해보면 아래와 같다.
T1 = w_records[5] * X +b_records[5]
T2 = w_records[15] * X +b_records[15]
T3 = w_records[75] * X +b_records[75]
plt.figure(figsize=(12, 8))
plt.scatter(X, y, c='black', alpha=0.5)
plt.plot(X, y_hat, c='red', lw=4)
plt.plot(X, T1, c='#3498DB', lw=3, ls=':', alpha=0.8)
plt.plot(X, T2, c='#FF5733', lw=3, ls=':', alpha=0.8)
plt.plot(X, T3, c='purple', lw=3, ls=':', alpha=0.8)
plt.grid()
plt.show()
위 기초코드에 대한 세부설명은 ChatGPT에 물어보면 상세히 설명해준다.
Linear regression (2)
1) 데이터 읽기 (당뇨병 예측 데이터)

먼저!
X 를 Feature, w 를 가중치 벡터, y를 Target이라고 할 때,
역행렬이 존재 한다고 가정했을 때, 아래의 식을 이용해 w의 추정치를 구해보자.

2) Shape 확인 및 정리

3) w 정리


- 참고
- tf.linalg.inv( ) 는 항상 오류가 난다. tensorflow, CUDA, cuDNN 전부 삭제 및 재설치 했지만 계속 오류가 난다.(cuSolverDN 인스턴스를 생성하는 데 실패)
- tensorflow로 계산하지 말고 numpy로 동일하게 계산되니, 그렇게 진행 (np.linalg.inv( ))
- w 계산에서, X라는 행렬이 정사각 행렬이면 역행렬이 존재하여 바로 곱하면 되지만,
- 정사각 행렬이 아닌 경우, 전치행렬을 곱하여 정사각 행렬을 만든 이후 역행렬을 사용해야 한다.


4) SGD 방식으로 구현
- Conditions
- steepest Gradient Descents
- 가중치는 Gaussian Normal Distribution에서의 난수로 초기화함
- step size = 0.03
- 100 iteration


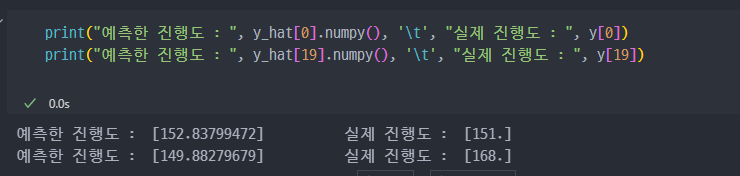
처음에 전치, 역행렬 계산을 통해 구했던 것보다, SGD 방식으로 학습하고 구현한 게 훨씬 정확도가 높은 것을 알 수 있다.
Perceptron
Perceptron은 Frank Rosenblatt가 1958년에 제안한 가장 기본적인 형태의 인공신경망 모델로, 머신러닝과 딥러닝의 기본이 되는 개념입니다. Perceptron은 단층 신경망(Single-Layer Neural Network)의 한 종류로 볼 수 있으며, 이진 분류 문제를 해결하기 위해 설계되었습니다.
Perceptron은 기본적으로 선형 분류기를 의미하며, XOR 문제와 같이 선형적으로 분리할 수 없는 문제를 해결할 수 없다는 한계가 있습니다. 이를 극복하기 위해 다층 퍼셉트론(Multilayer Perceptron, MLP)이 사용됩니다. 다층 퍼셉트론(Multilayer Perceptron, MLP)은 여러 개의 은닉층을 추가하여 비선형성을 도입하고, 복잡한 문제를 해결할 수 있습니다.
Perceptron은 신경망의 기본 개념을 이해하는 데 중요한 역할을 하며, 현대 딥러닝 모델의 기초가 됩니다


데이터 읽기
sikit-learn에 저장되어 있는 iris 데이터 읽기 진행.


perceptron은 이진 분류 문제에 적합하도록 설계되어 있으므로, feature와 분류값을 특정해서 진행한다. 2개의 feature 그리고 2개의 분류값(Setosa, Virginica)
데이터 전처리
데이터 정리, Sepal에 대한 특성값 그리고 Setosa, Virginica에 대한 값들만 추출해서 정리해야 한다.

먼저 target 데이터에서 0 - (Setosa)과 2 - (Virginica)는 각각 50개씩 존재.
마스킹 하기 위해서 np.in1d 사용


마스킹 진행해서, X_data에는 Sepal에 대한 특성정보만 저장. (Setosa 와 Virginica에 해당하는)
y 값에서는 0, 2로 분류되는 것들을 -1 과 1 로 변환하고

shape 변경 (np.newaxis)

np.newaxis : 차원확장 시 사용

결국 X_data 와 y_data 의 shape은

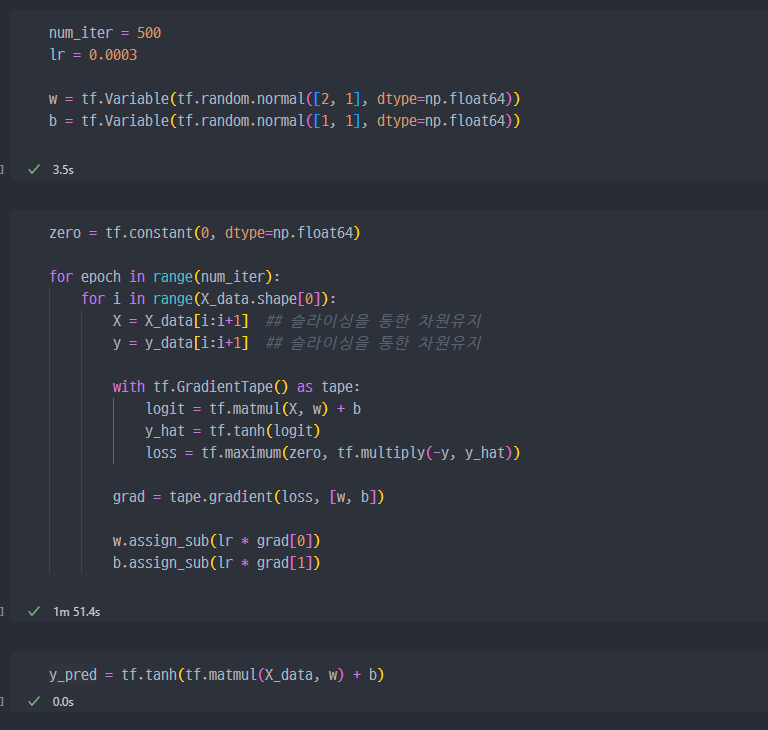
학습 진행
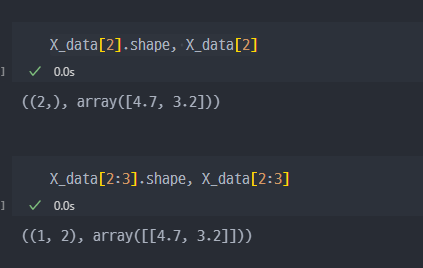
슬라이싱을 통한 차원유지.
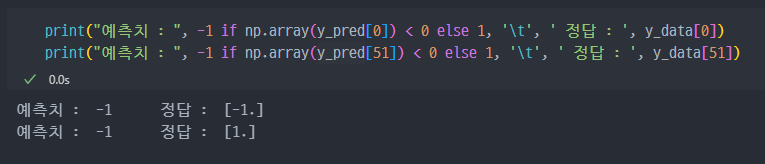
강의와 동일하게 진행했는데, 예측성능이 좋아보이지 않는다. 이에 대한 고민은 나중에 해야할듯 하다.
'Bootcamp_zerobase > Tensorflow' 카테고리의 다른 글
| SubClass 모델링 : SubClass 및 모델구현 (0) | 2025.04.07 |
|---|---|
| Functional Modeling : Functional API 및 간단한 ResNet 구현 (0) | 2025.04.03 |
| CNN (VGGNet) #1 (0) | 2025.04.01 |
| Tensorflow #3 : 딥러닝의 흐름, 간단한 Model 학습 (1) | 2025.03.31 |
| Tensorflow #1 : 텐서플로우 기본개념 (1) | 2025.03.27 |