
2025.03.11
Chapter 8. YOLO & Chapter 9. RNN
- 52. YOLO - 배경
- 53. YOLO - 배경
- 54. YOLO - 학습법
개념복습
Classification vs Clustering
■ 복습차원에서 다시 한 Classification(분류) 과 Clustering(군집)를 보면

군집화 (Clustering)의 큰 특징은 label(정답값)이 없고 데이터의 특성, 특징에 의해 스스로 클래스를 분류하는 것이다.
Classification vs Regression
■ 그러면, Classification과 Regression(회귀)의 차이를 보면,
Regression(회귀)은 어떤 데이터에 대해 "대표"할만한 데이터를 만들고 연속적으로 예측하는 것.
Class(label) vs Feature(column)
■ Class 와 Feature
Clf Using DL
■ Classification using Deeplearning
사실 딥러닝이 두각을 나타내고 있는 분야는 이미지 처리분야이다.
MLP vs CNN
■ Deeplearning으로 이미지를 다룰때의 문제점
이미지 분류에서 MLP의 경우 조금만 이동해도 정답값으로 분류하지 못한다.

CNN은 특성을 찾기때문에 이미지 분류 문제에서 많이 적용된다.
여기서 다시 MLP와 CNN을 보면..
1. MLP (Multi-Layer Perceptron)
MLP는 완전 연결 신경망 (Fully Connected Neural Network)이라고도 불립니다. 모든 노드가 이전 층의 모든 노드와 연결되어 있는 구조를 가집니다.
주요 특징:
- 구성: 여러 개의 층 (Layer)이 있으며, 각 층의 뉴런들이 이전 층의 모든 뉴런과 연결됩니다.
- 주요 용도: 주로 일반적인 예측 문제나 분류 문제에서 사용됩니다.
- 활성화 함수: 각 층에서 비선형성을 주기 위해 보통 ReLU (Rectified Linear Unit) 같은 활성화 함수를 사용합니다.
- 장점: 구조가 간단하고, 특정 형태의 입력 데이터에서 잘 작동합니다.
- 단점: 이미지나 시퀀스 데이터와 같이 공간적 구조나 순차적 정보가 중요한 데이터에는 성능이 떨어질 수 있습니다.
2. CNN (Convolutional Neural Network)
CNN은 주로 이미지 처리와 관련된 문제를 해결하기 위해 설계된 신경망입니다. 합성곱 층(Convolutional Layer)을 사용하여 입력 데이터를 처리합니다.
주요 특징:
- 구성: 기본적으로 합성곱 층, 풀링 층(Pooling Layer), 완전 연결 층(FC Layer) 등을 포함하고 있습니다.
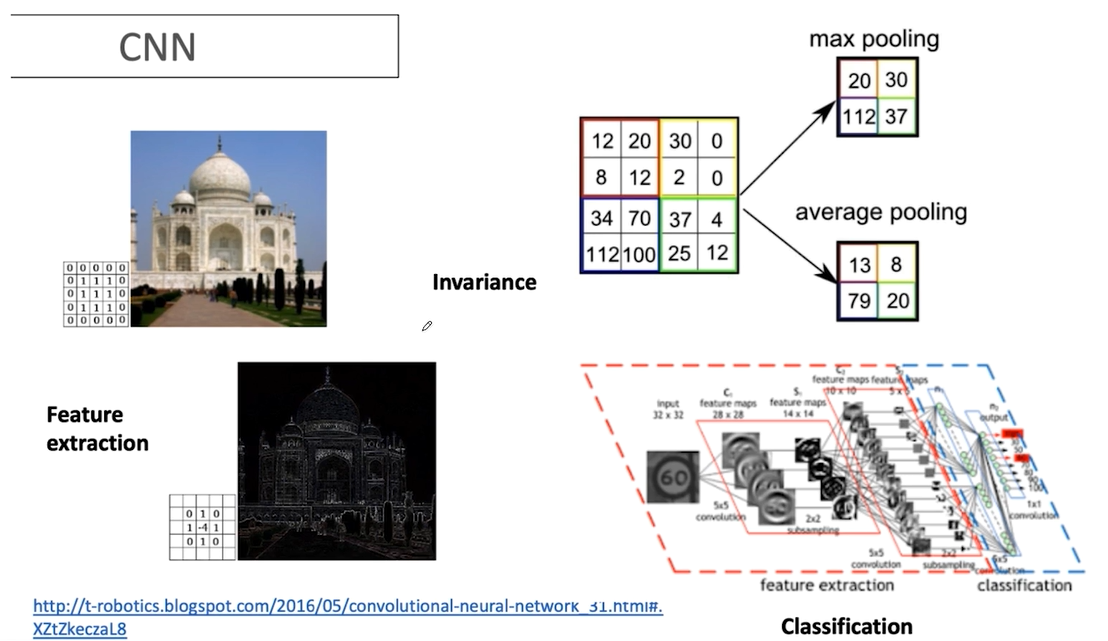
- 합성곱 층: 이미지에서 중요한 특징을 추출하는 역할을 합니다.
- 풀링 층: 이미지의 크기를 줄여주는 역할로, 주로 Max Pooling이나 Average Pooling을 사용합니다.
- 완전 연결 층(FC Layer): MLP처럼, 합성곱 층에서 추출된 특징을 이용하여 최종 예측을 합니다.
- 주요 용도: 이미지 처리, 영상 인식, 음성 인식, 자연어 처리 등에서 뛰어난 성능을 보입니다.
- 장점: 공간적 구조를 유지하면서 중요한 특징을 자동으로 학습합니다. 전역 특징과 지역 특징을 잘 추출하여 효과적인 학습을 합니다.
- 단점: 상대적으로 복잡한 구조로, 더 많은 계산 리소스를 필요로 합니다.
3. MLP와 CNN의 차이점
- 구조: MLP는 완전 연결된 네트워크로, 입력 데이터의 모든 특성을 동시에 처리하는 반면, CNN은 합성곱 연산을 통해 공간적, 지역적 특징을 추출합니다.
- 입력 데이터 처리: MLP는 벡터 형태의 데이터를 다루며, CNN은 이미지와 같은 2D 데이터나 3D 데이터를 다룰 때 성능이 뛰어납니다.
- 용도: MLP는 일반적인 예측과 분류 문제에서 사용되며, CNN은 이미지와 같은 고차원 데이터에서 특히 효과적입니다.
(Multi) Object Detection

단순 분류가 아닌, 한 이미지안에서 여러 물체에 대한 Class 분류하는 것.
어떻게 이렇게 분류할 것인가는 큰 틀에서 아래의 두 가지가 가장 먼저 주목받기 시작했다.

가로축을 기준으로 위쪽에 위치한 모델들이 2-Stage Detector 라 불리며, 아래쪽에 위치한 모델들이 1-Stage Detector 로 불리운다. 그 중 가장 많이 주목받은 Detector가 YOLO와 SSD 이다.
1 or 2 Stage Detector
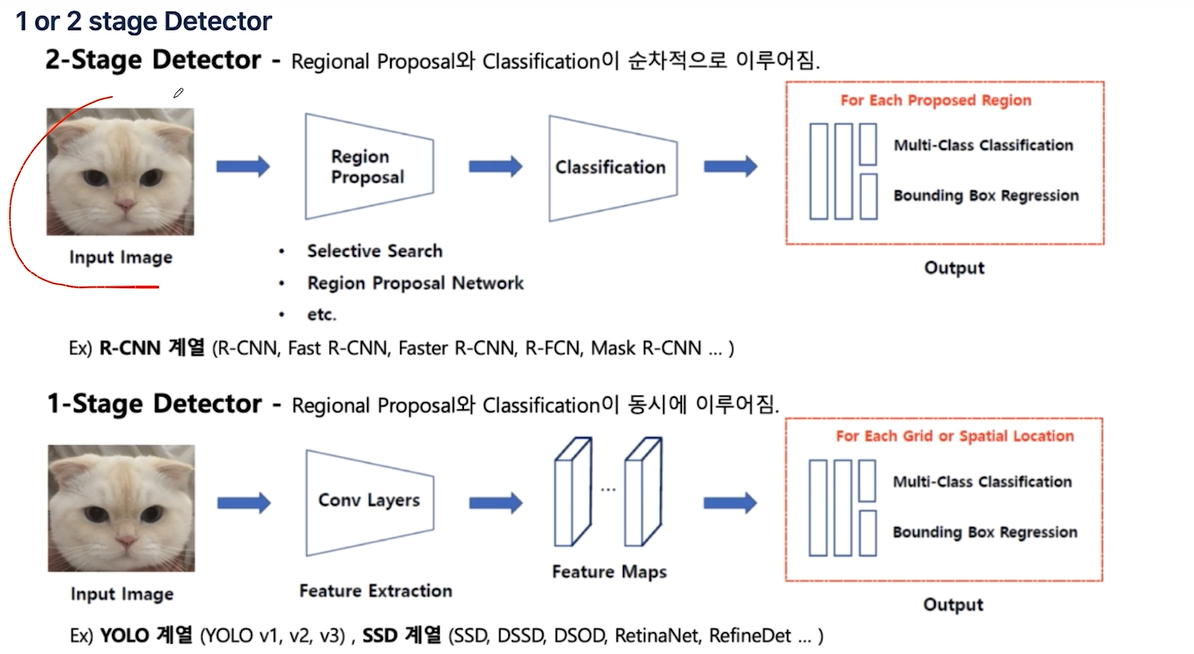
R-CNN 계열처럼, ①인식해야 할 사물이 존재할법한 영역을 먼저 찾고, ②그 영역에 무엇이 있는지 분류하는 것이 2-Stage Detector라고 한다.
1-Stage Detector는 영역과 물체분류를 동시에 한다. 다만, 하나의 이미지를 여러개의 그리드로 분리시킨 후 각 그리드를 Detection 진행한다. 이 것이 YOLO 이다. (You Only Look Once). 당연히 2-Stage Detector보다 빠를것으로 생각된다.
YOLO란?
위에서 배웠지만, YOLO에 대해 학습한다. 다시 생각해봐도, You Only Look Once는 재미있는 이름인것 같다.
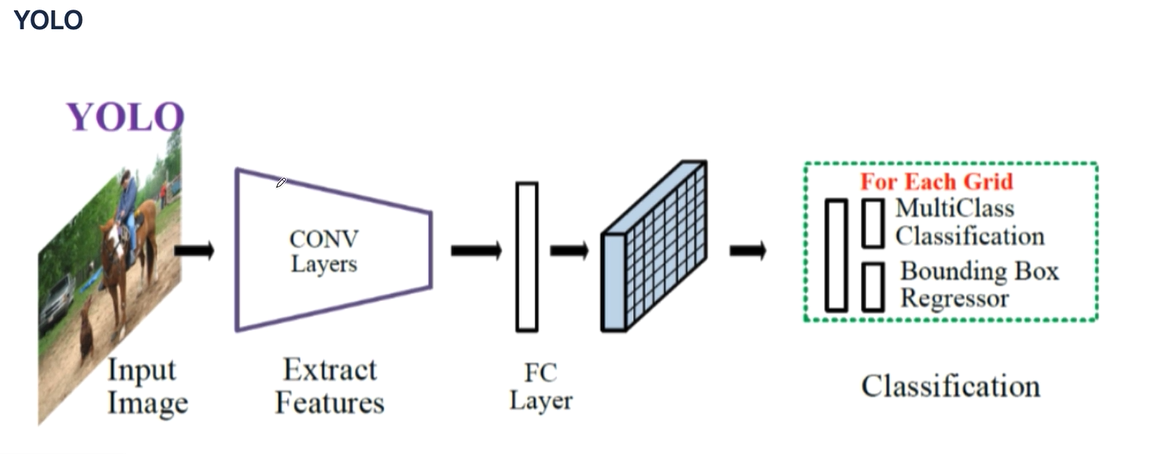
YOLO는 FC Layer 이후에 그리드(Grid)가 적용된다. 그리고 각각의 Grid에 대해서는 회귀(Regression)를 적용하고, 라벨에 대한 인식은 분류(Classification)을 적용한다. 또한 기본적으로 YOLO는 GoogleNet을 이용한다.
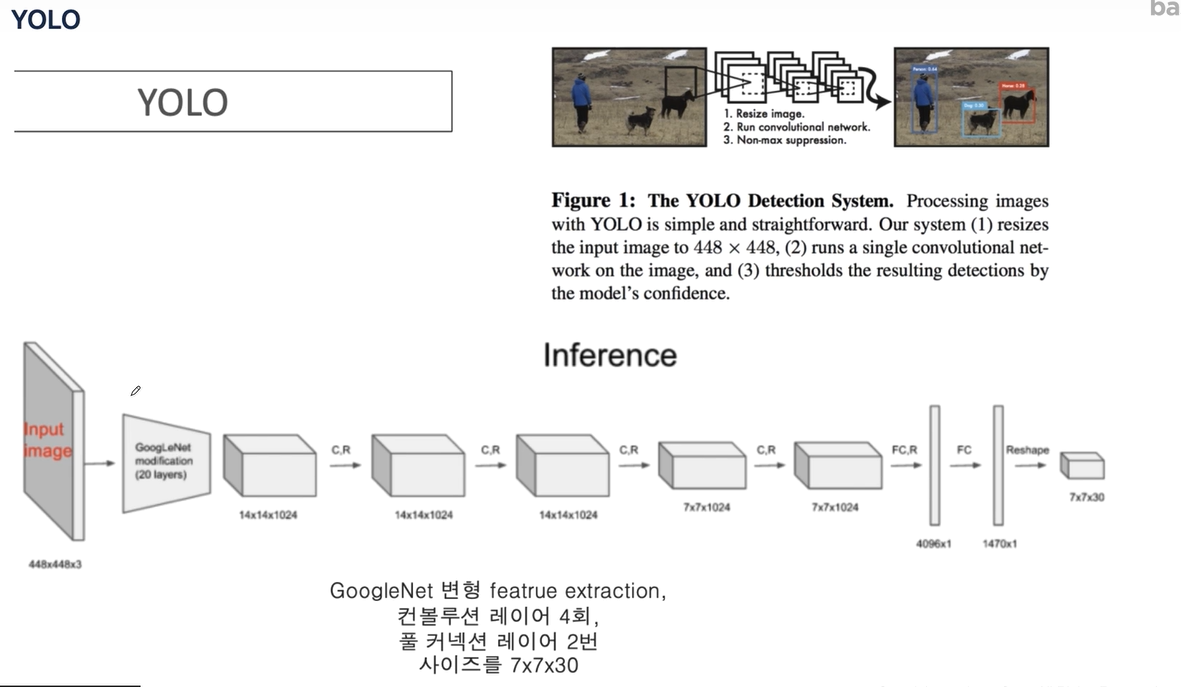

위 그림의 각 그리드마다 여러개의 계층/layer/채널로 구성되어 있으니 사실 깊다(?). 말이 애매하긴 한데, 사실 Conv layer 자체가 16, 32, 64로 채널이 증가되니 입체적으로 이해할 수 있다.
v3 버전 기준으로 30차원이 grid cell에 저장된다.
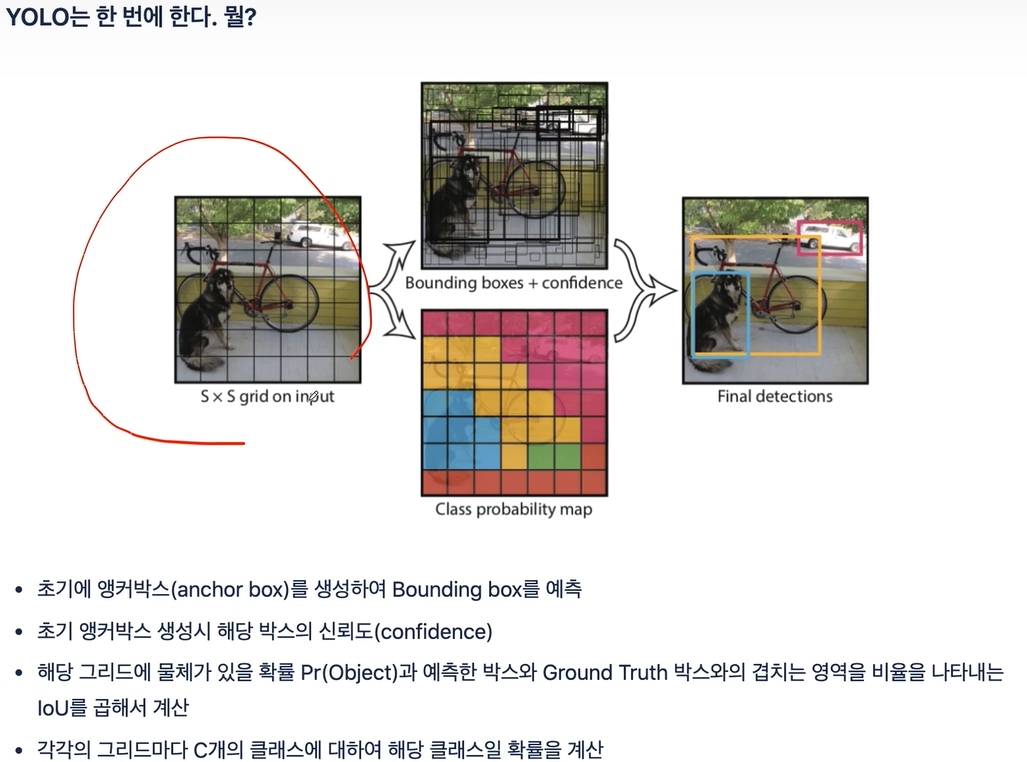
Ground Truth는 라벨값(정답값)으로 이해하면 된다.
정확하게 이해하기 위해서는, 관련 논문을 조금 읽어야 되겠다. 간단하지는 않은 개념으로 생각된다.
'Bootcamp_zerobase > YOLO & RNN' 카테고리의 다른 글
| RNN #2 (1) | 2025.03.26 |
|---|---|
| RNN #1 (0) | 2025.03.23 |
| YOLO #2 (0) | 2025.03.21 |